创建IP源
创建IP源
当系统完成安装之后,第一件事情就是考虑如何接入ip源,这里我们对ip源接入进行讲解
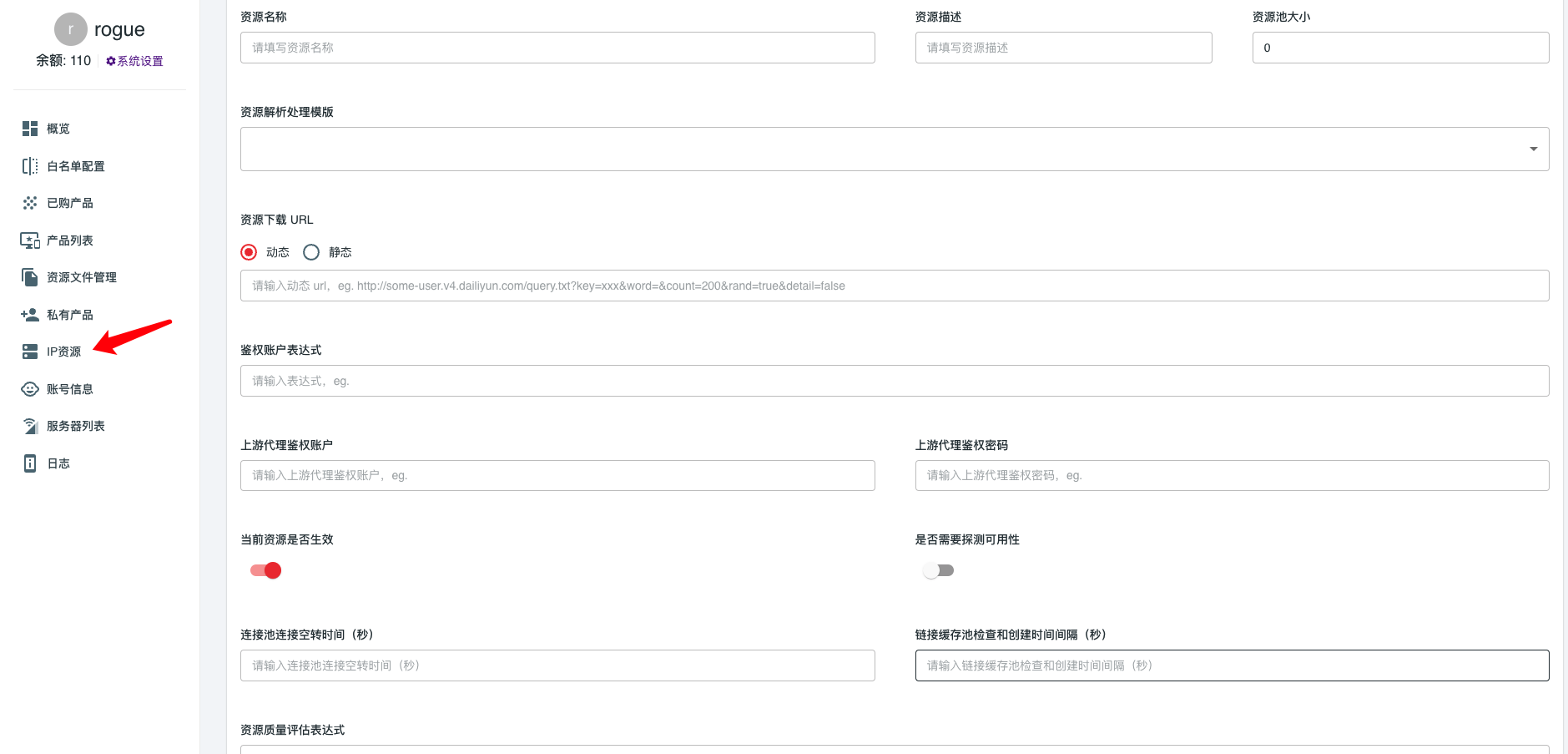 添加ip资源是一个相对比较复杂的任务,根据上图,我们逐一解释每个配置项的含义。在你没有足够指导的时候,你可以考虑联系我们的商务获得配置任务的帮助。
添加ip资源是一个相对比较复杂的任务,根据上图,我们逐一解释每个配置项的含义。在你没有足够指导的时候,你可以考虑联系我们的商务获得配置任务的帮助。
资源名称
每个ip资源都需要有一个名称,名称建议使用英文+数字表示。汉字在这里是不被建议的
资源描述
随便描述下方便查找
资源池大小
非常重要,请您自行根据你对将要接入的ip的容量大小做一个评估。资源池大小是系统ip池在处理池化逻辑非常重要的参考,我们在考虑替换和下线ip的时候需要考虑ip池的总容量才能指定更加优异的ip切换方案。
需要注意的是,这个大小不是那些代理ip供应商宣传的每日ip几百万的概念,他只代理服务节点数。数量一般在几十到几百之间,只有大型互联网自己建立的代理ip网络才可能达到上千!!!
资源下载URL
资源下载URL的主要职责是获取上游代理ip供应商的代理ip列表。
- 有些代理ip供应商提供的是一个url,我们通过访问URL下载到代理ip资源。
- 有些代理ip供应商提供的是一个特定的ip+一个特定端口范围。此时不需要通过url下载
所以获取代理ip主要有两种方案,1通过url下载,2直接把配置发给客户。那么我们这里的资源下载URL字段就有两种配置,分别为静态URL和动态URL。
- 如果你的代理ip是需要通过url下载的,那么填入你的下载url即可,url类型选择动态。
- 如果你的代理ip不需要通过url下载,而是固定的一个服务器和固定端口。那么按照规则填入这个服务器和端口即可。同时url类型选择静态。
上游代理鉴权账户 && 上游代理鉴权密码
供应商给你提供的账户密码,如果ip供应商是白名单ip鉴权,那么这里也可以不用填写。
是否需要探测可用性
如果开启,一个ip从ip供应商下载,导入到malenia系统之后,需要被malenia进行代理连通性测试之后才会被真的加入到ip池中。如果你对你的ip供应商质量足够自信,那么可以关闭这个开关。
资源指令评估表达式
质量评估表达式的作用是用于定义ip质量,他的格式如:60<35|20<70|20<80,
IP下载时间间隔(秒)
如果上游ip池提供的是ip列表,那么需要我们以一定频率的方式下载ip。正常情况这个数值应该是ip供应商供应的ip过期时间间隔的65%左右即可
IP源支持协议
定义你的ip源所支持的代理协议,逗号分割。目前可以定义的为:HTTP、HTTPS、SOCKS4、SOCKS5
最长存活时间(秒)
ip供应商告诉你的ip切换时间,如果你是长效IP,可以设置为一个很长的数,并且对于长效如果最长存活时间小于IP下载时间间隔,那么ip约等于永久有效
隧道路由参数
隧道路由参数定义了通过账号传递参数控制单个代理请求行为,但是实践过程很少有人使用这么复杂。你只需要知道通过账户密码鉴权控制各种代理行为就可以了。 当你真的需要这个功能的时候,建议你联系商务
资源处理模版
资源处理模版主要用来解析下载到的代理ip配置,这也是因为代理ip供应商提供的代理ip的多样性可能提供的抽象。请根据代理ip供应商给你提供的代理ip格式选择特定模版。
目前malenia提供的资源处理模版有两种,分别为: IpPortPlain和PortSpace
IpPortPlain
ip和端口列表,按行(\n)分割,每一行一个代理ip资源,国内大多数代理ip供应商都是提供这种格式。 如:
182.244.169.248:57114
113.128.31.3:57114
36.102.173.123:57114
182.38.126.190:57114
如上demo,ip供应商返回了4个代理ip,分别为4个ip的57114端口。
PortSpace
一般提供单个服务器+多个端口映射的供应商会提供这种格式的代理ip配置。多个代理服务器使用英文逗号分割。对于每个代理服务器,可以配置一个端口范围。使用"-"分割范围起始 如:
haproxy1.dailiyun.com:20000-20200,haproxy2.dailiyun.com:20200-20500
如上demo,ip供应商提供了500个代理,其中haproxy1.dailiyun.com提供200个代理,haproxy2.dailiyun.com提供300个代理。
使用脚本定义解析模版
一般情况下国内的ip都是使用如上两种格式供应,但是有一些特殊的厂商非常奇葩,比如传说中的芝麻代理(芝麻代理资源过期不下线,反而在http层面返回失败,导致我们的中转代理系统必须侵入到http内容进行判断才能判定ip资源不可用)。 为了让我们的系统能够处理任何代理资源厂商的ip资源,我们在供应商提供的代理格式上面提供代理ip解析脚本功能,让用户可以完全的编程控制代理解析。
- 在脚本中你可以定义多个解析器,用于处理多个ip厂商资源
- 你需要将这个脚本配置到 系统设置 -> 扩展ip解析器
- 在脚本中,我们可以定义更加完整的代理ip属性
- 对于单个ip配置账号密码
- 解析ip的过期时间:正常情况malenia系统通过ip本身的连通性和全局配置来控制一个ip不可用时机,但是这种配置对于芝麻代理来说是不可靠的。所以芝麻代理必须使用脚本控制精细的过期时间
- 脚本格式是groovy,在这里你可以使用一些java的lib库(不可以自己额外导入)。关于groovy我们有详细的章节介绍,请关注groovy相关
一个合法的脚本如下:
import com.google.common.base.Splitter
/**
* 使用groovy脚本定义代理资源入库脚本
*/
//http://xxx.v4.dailiyun.com/query.txt?key=xxxx&word=&count=50&rand=true&detail=true
DefineParser {
name "DailiYunDetail"
demo "183.165.128.141:57114,183.165.128.141,中国-安徽-淮南--电信,1650093710,1650094010\n" +
"183.165.128.141:57114,183.165.128.141,中国-安徽-淮南--电信,1650093710,1650094010"
desc "代理云详情解析器,这个解析器可以支持ip过期时间"
parse({
content ->
content.toString().split("\n").split {
addProxy({
List<String> strings = Splitter.on(",").splitToList(it.toString())
ipAndPort strings.get(0)
// 请注意,如果你在代理资源整体配置过账户密码,那么这里可以不用为单个代理资源陪配置密码
userName null
password null
expireTime Long.parseLong(strings.get(3))
})
}
})
}
账户鉴权表达式
请注意,大部分情况下国内ip供应商你不需要填写本字段,因为国内供应商目前没发现有需要这个功能的场景,本方案主要用于对接海外的资源供应商,在海外业务使用
这是一个非常复杂的概念,部分供应商通过帐密的方式进行代理方案路由转发。用来保持session和决定代理ip类型。 所以当上游服务支持鉴权表达式的时候,我们需要完成malenia鉴权帐密里面的路由参数的解析和重组,完成路由参数的透穿(最大范围完整支持上游ip供应商特殊功能)。
首先给两个简单的表达式样例,感受下他的真实规则:
- 默认无定制表达式:
${user,,$value} - luminati表达式:
${user,,$value}${country,__drop,-country-$value}${session,__drop,-session-$value}${zone,-zone-zone1,-zone-$value}${route_err,__drop,-route_err-$value}
表达式变量
上游代理密码和从下游传递过来的路由参数,都会被打包到一个变量环境中。之后我们可以在上游表达式中使用这些变量。
curl --proxy malenia.iinti.com:22225 --proxy-user malenia_customer_c_9a85388b-zone-zone1-country-us-session-1234:malenia_password "http://lumtest.com/myip.json"
malenia接收到上述代理请求之后,将会解析出如下属性信息
- user: malenia_customer_c_9a85388b
- zone: zone1
- country: us
- password: malenia_password
- session: 1234
其中代理账户和代理密码将作为真正的代理帐密鉴权数据执行鉴权操作,鉴权通过之后,创建到luminati的连接,将会尝试进行和luminati的鉴权。
此时账户密码将会被替换成luminati给我们提供的帐密内容,得到如下新的属性信息
- user: lum-customer-c_9a85388b
- zone: zone1
- country: us
- password: qtsqyds26lse
- session: 1234
上述即为给上游代理luminati的鉴权表达和变量。在构造到luminati的鉴权账户字段时候,我们将会通过表达式:${user,,$value}${country,__drop,-country-$value}${session,__drop,-session-$value}${zone,-zone-zone1,-zone-$value}${route_err,__drop,-route_err-$value} 进行规则叠加,得到如下内容: lum-customer-c_9a85388b-zone-zone1-country-us-session-1234
然后转发如下内容到luminati的服务器
curl --proxy zproxy.lum-superproxy.io:22225 --proxy-user lum-customer-c_9a85388b-zone-zone1-country-us-session-1234:qtsqyds26lse "http://lumtest.com/myip.json"
变量节
满足如下样例: ${country,__drop,-country-$value}的表达式,即为一个变量节,表达式变量为多个变量节和常量节顺序组成。 变量节的规则为:${变量名,空处理函数,拼接表达式}
- 变量名为当前变量节处理的对应变量,在制定变量名之后,表达式引擎将会得到对应的value,并且在
拼接表达式中可以通过$value对他进行引用。 - 空处理函数为当该变量不存在(下游没有传递的时候),输出的结果的处理逻辑。他可以是一个新的变量节、常量节、或者
__drop - 拼接表达式是最终输出规则,他可以引用
$value,动态生成一个字符串
需要注意的是,空处理函数中,__drop拥有特殊功能,他的含义是,如果当前变量节的变量在变量表中不存在。那么改变量节的拼接表达式将不会生效,而是直接构造为一个空字符串。
另外,如果你的表达式内容中,存在特殊字符,那么可以通过单引号或者双引号包裹。解除二义性差异问题。
常量节
常量节就比较简单了,在${变量名,空处理函数,拼接表达式}之外的其他内容,都会被分割为常量。表达式引擎不会对他们做解释,而是直接抽取字面量拼接为最终的输出。